GLSL & Sound
WDF-based spectrograms
GitHub: soundshader.github.io
Demo: soundshader.github.io/hss?wdf=1
You’ll need to skillfully use WASD and QERF keys to move around and zoom-in/zoom-out.
As I was looking for interesting audio transforms, I came across the Wigner distribution function (or just WDF). The example on Wikipedia looks indeed interesting and it’s “sold” as a function that “provides the highest possible temporal vs frequency resolution which is mathematically possible within the limitations of the uncertainty principle” and thus “when a signal is not time limited, its WDF is hard to implement.” Turns out, WDF isn’t much harder to implement than plain FFT.
The definition of WDF is this:

It does an interesting trick: at every point in time it inverts the audio signal and multiplies it by its normal time-forward version. This makes sense because a periodic signal at time T would locally correlate with a time inverted version of itself, however in WDF this correlation isn’t time bounded, so if the signal is 1 hour long, WDF will multiply two one hour long signals to compute just one value at T. This seems meaningless at first glance, as the random contributions 30 mins away from the current moment would make WDF random, but a closer look reveals that if those far away contributions are indeed random, they would cancel out each other, and they do (to an extent). The complex exponent on the right is effectively the usual FFT on the forward-inverted correlation.
In practice, this means a simple algorithm to compute WDF:
- Take N samples at the current moment:
x[1..N] - Apply the Hann window to approximate cancellation of far-away terms.
- Multiply it by the reversed copy of itself:
y[1..N] = x[1..N] * x[N..1] - Stretch it to account for
x(t+tau/2)in the formula above:y[1..N/2] -> z[1..N] - Compute the usual
Z = FFT[z]
So it doesn’t really add any complexity on top of the regular FFT. In practice, though, WDF is an extremely noisy function that’s much less insightful than plain FFT. Below is the same bird recording (xeno-canto.org/33539) visualized with different methods.
- CWT with the Morlet wavelet.
- FFT with the Hann window function. This is practically equivalent to CWT, as the latter is more or less the same as FFT with the slightly different Gaussian window. And unlike CWT, computing FFT doesn’t involve any mental gymnastics.
- Plain FFT spectrogram with 1024 bins at 48 kHz. Pixelated because only 300 or so bins capture the useful 0..8 kHz range.
- “Continuous FFT” spectrogram that uses the DFT Shift Theorem and the usual rectangular window function which produces these sinc-shaped diffraction patterns.
- WDF with the Hann window on 2048 samples per frame.
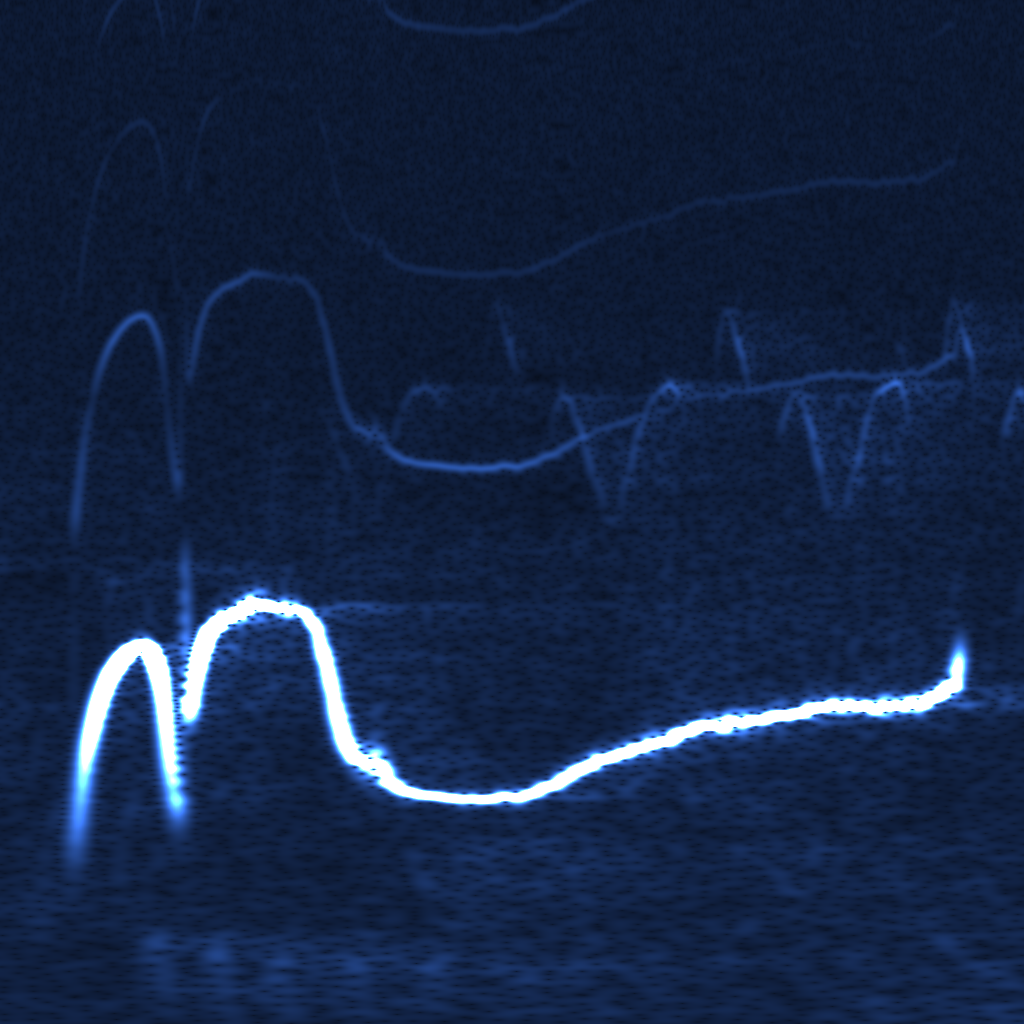
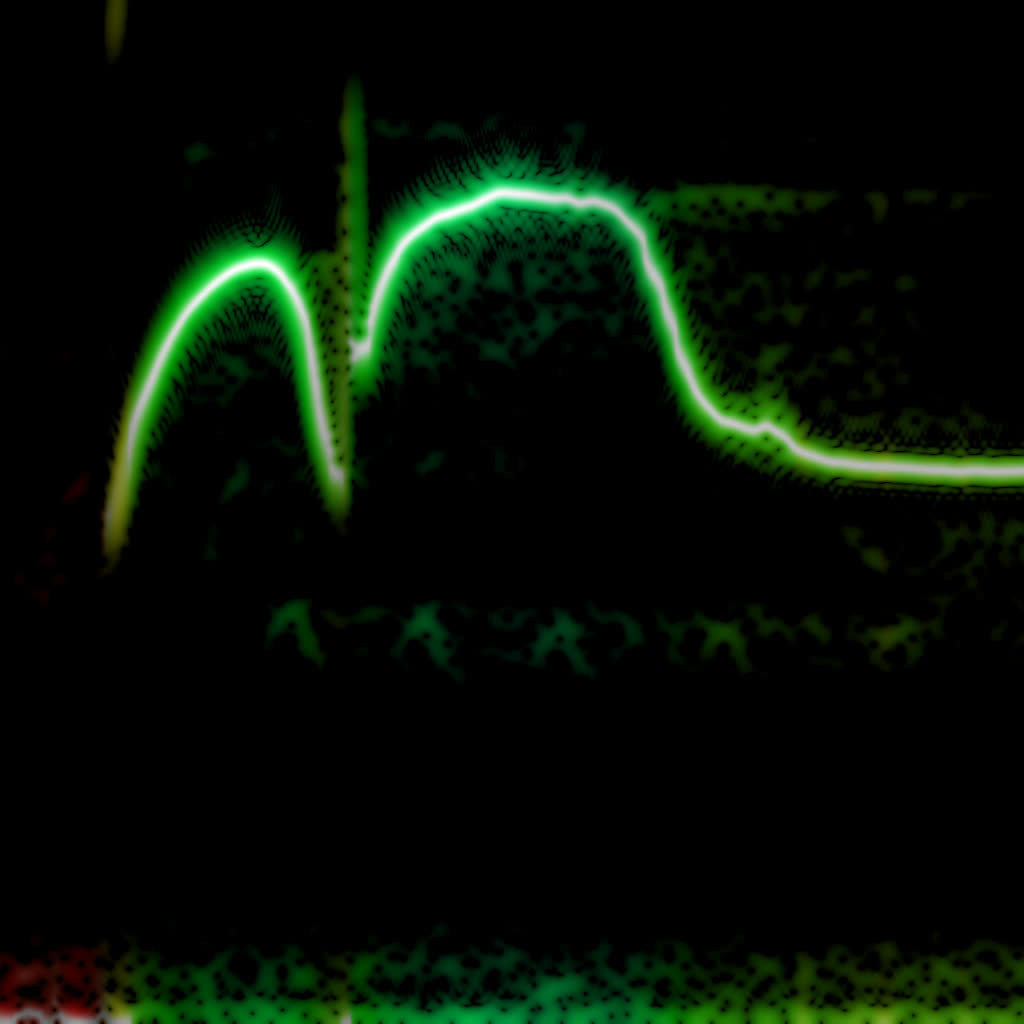

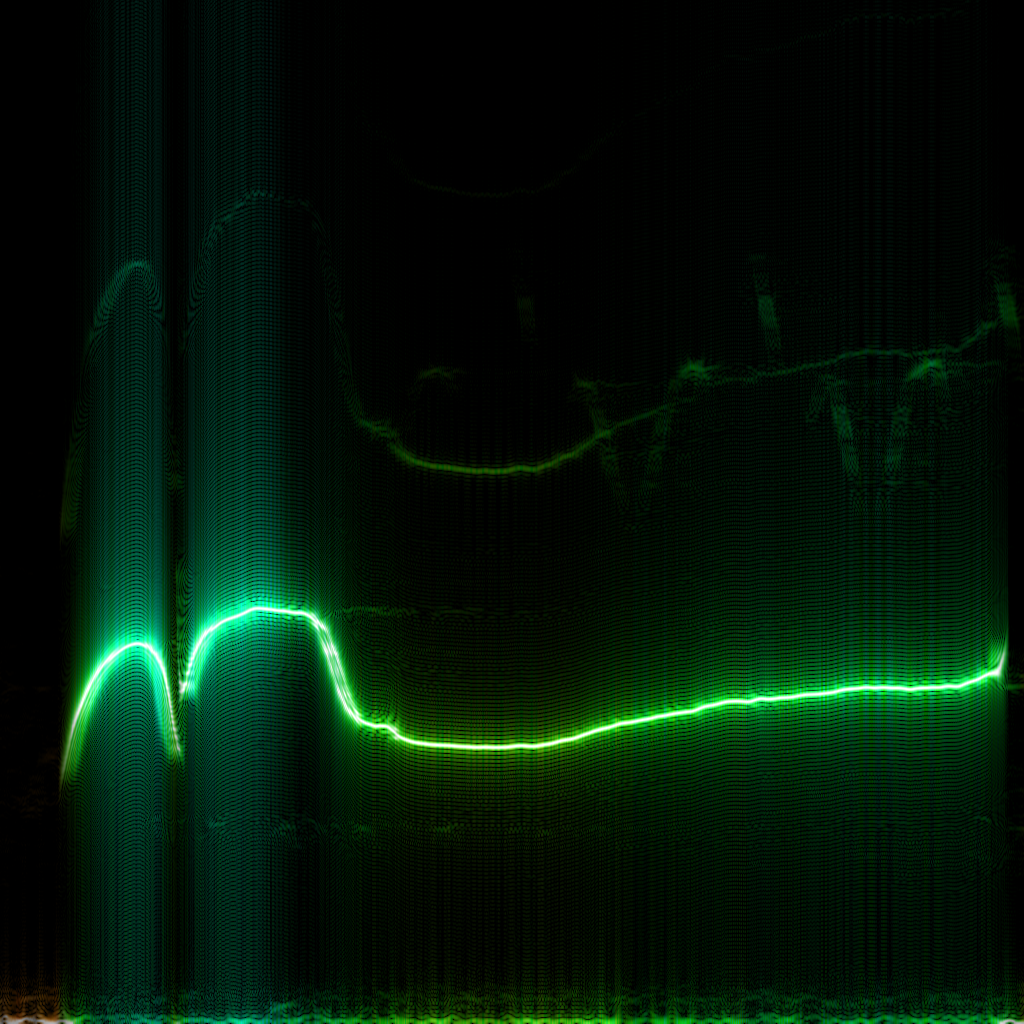
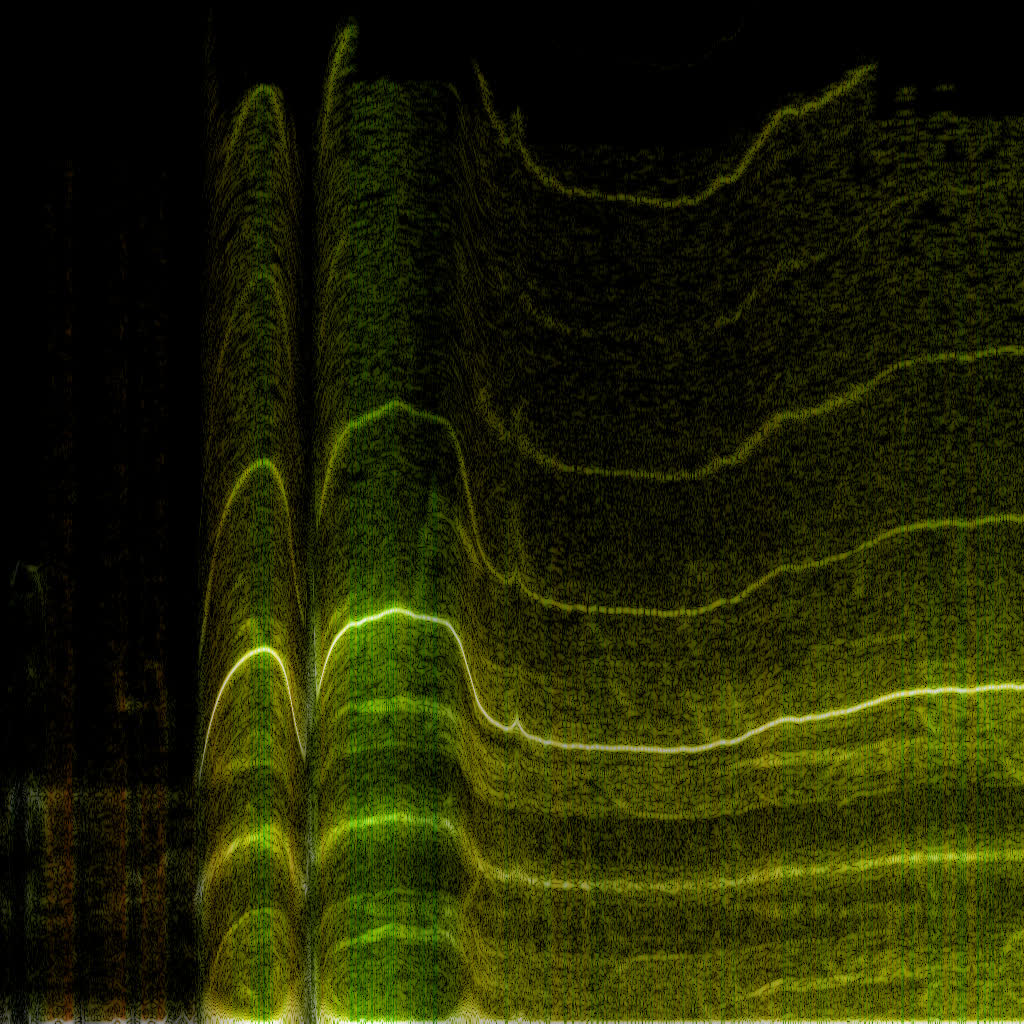
WDF is able to produce interesting spectrograms sometimes, but in most cases it’s unusably noisy. Unlike FFT spectrograms, WDF gets more precise on larger windows: frequency lines get thinner, at the expense of adding more noise around them. Below is the same violin sample: an FFT spectrogram, and two WDF spectrograms with 2048 and 4096 samples per frame.



Some bird examples: WDFs with 2048, 4096 and 8192 samples per frame.
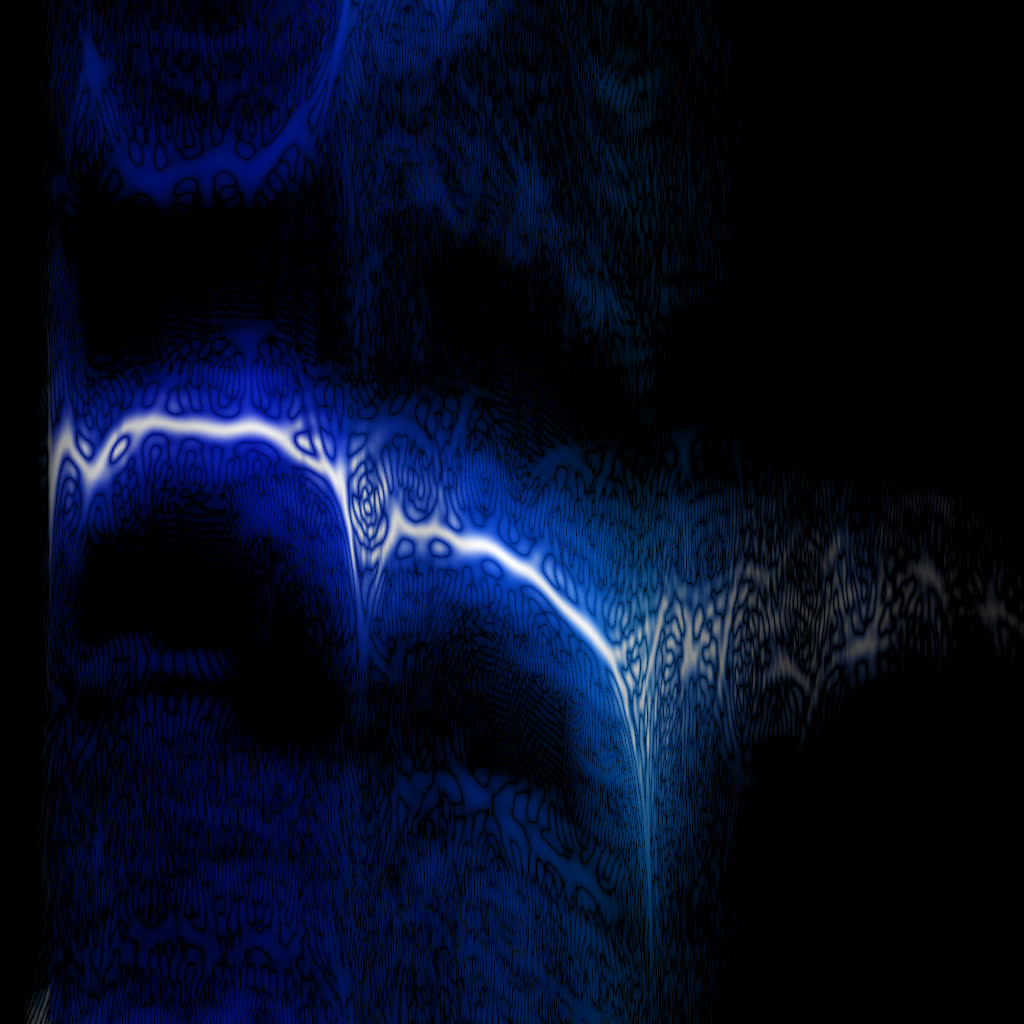
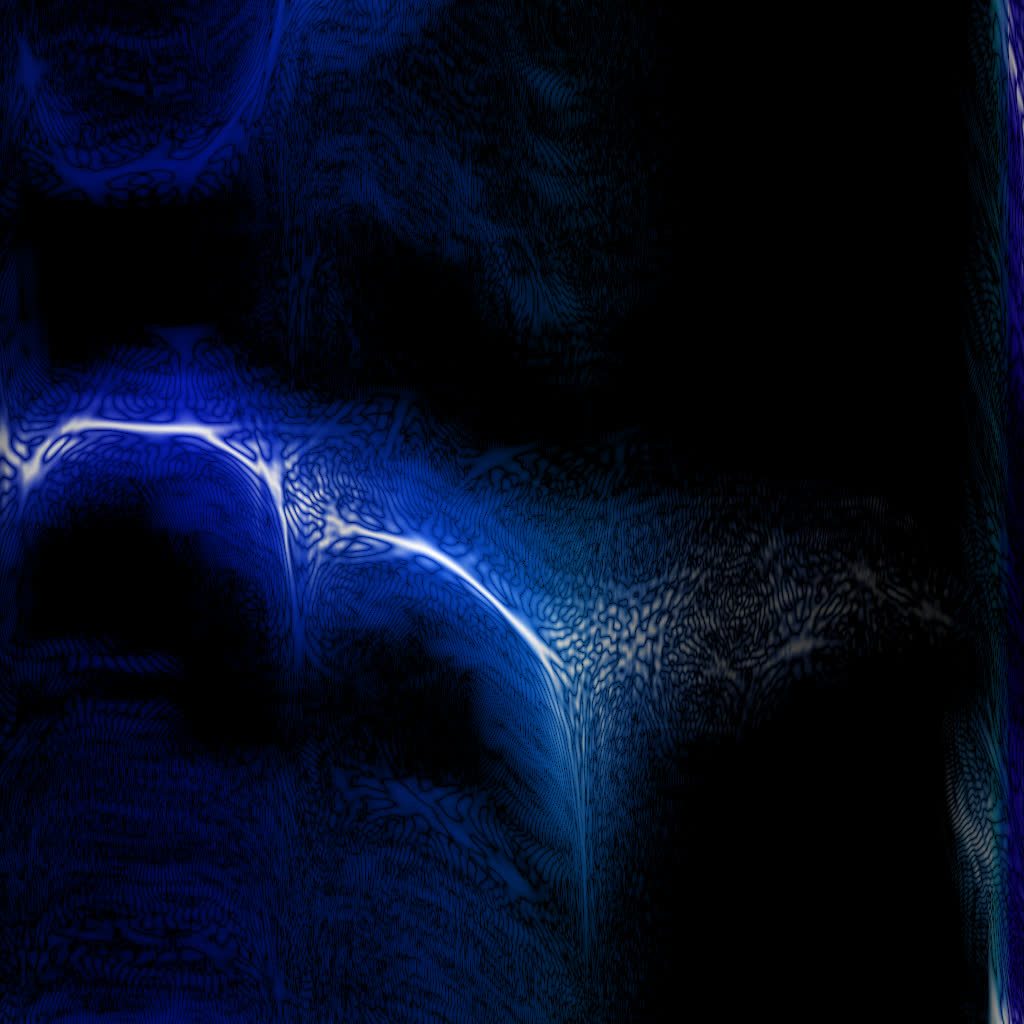

For some reason WDF is miles ahead on simple tibetian bowl sounds (that turn out to be not that simple). This is the same 500 ms of sound, the 0..3 kHz range (use ?wdf=1&alog=3&bins=4096 args):


A few more bowl examples (all WDF):












Appendix
I’ve accidentally discovered that a lazy ffmpeg -i bird.mp3 bird.ogg produces audio artifacts. Even though they are inaudible, they can be easily seen on spectrograms.
The original mp3 (libvorbis) and transcoded ogg (default libvorbis, -compression_level 10):



Transcoded ogg (default libopus, -b:a 48k, -b:a 48k -compression_level 10 and just -compression_level 10):




The interesting conclusion is that specifying the correct bitrate (48k) achieves the highest quality and the smallest file size as a bonus. Even the additional “best compression” option has no visible effect. Just -compression_level 10 produces artifacts, as ffmpeg sets bitrate to 64k for some reason. I couldn’t get -codec:a libvorbis to produce a good result. It must work somehow as libvorbis is used in the mp3 file, but I couldn’t figure the right set of ffmpeg options. Here’s the winner command line:
ffmpeg -i XC33539.mp3 -codec:a libopus -b:a 48k XC33539.ogg